备注:本篇基于1.7或者1.6的jdk。
由于为规范使用线程池导致生产环境出现了CPU使用率持续飙高,并且不下降,很诡异的是几十台服务器只有一台机器出现了问题,只能重启服务器解决,最后通过分析dump文件发现是因为在多线程环境下使用HashMap导致的。在此分享出来给大家共勉。
事情起因
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| public static void main(String[] args) throws Exception {
ThreadPoolExecutor poolExecutor = new ThreadPoolExecutor(
2,
10,
2,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(10));
Map<String, Integer> params = new HashMap<>();
params.put("k1", 123);
for (int i = 0; i < 50; i++) {
poolExecutor.execute(() -> {
Map map = doSomething();
params.putAll(map);
});
}
}
|
由于在使用线程池时不规范,直接把params传入并且对这个Map频繁执行putAll()操作,导致链表发生死循环。忽视了HashMap最基本的特性,它是线程不安全的。
问题代码:
这个链表死循环只有在特殊场景下才会触发,所以代码上线很久都没有出现问题,并且只是其中某台服务器出现问题。这种问题定位分析起来非常麻烦,不触发还好,触发了就只能等着死机重启。
在说明链表死循环之后,我们先来了解一下HashMap是一个什么数据结构。
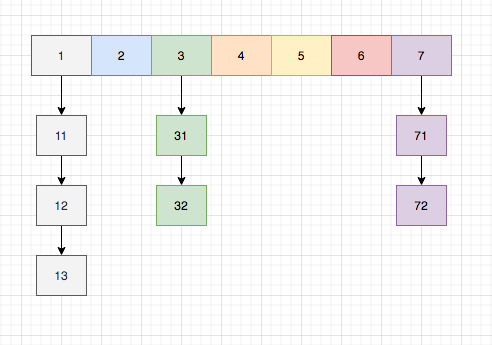
在HashMap内部,首先定义了一个数组,数组的元素类型是Map.Entry 对象,如下是源码的数组定义:
1
| transient Entry<K,V>[] table
|
对应到上图就是第一行所示。
当调用put(key, value)方法时,首先使用key计算哈希值,然后再用得到的哈希值和数组长度取摸(hash % table.lenght)。得到的值就是数组的下标,然后把value放在下标对应的位置上。
如果有两个key计算得到的下标是一样,那么就会把新增的value以链表的方式连接到同一个下标位置上。比如上图的31,32。
当数组达到阈值(长度的0.75倍)时,就会发生扩容,把数组扩大为原来的2倍。比如上图数组长度是7,那么阈值就是5.25,取整后就是5。当1,2,3,4,5这几个位置都有元素了,在新增元素计算后的下标是6的情况,就会发送扩容。扩容时会新建一个数组,然后把元素复制到新的数组上。复制的过程会对每个key重新计算哈希值,再计算下标,因为数组长度变了,下标自然也会变。
如果有新增的元素则循环往复执行上述3步。原理是比较简单的,在看下源码实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key);
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
|
新增元素
新增元素时先判断是否需要扩容,如果不需要则直接新增,否则扩容再复制。
1
2
3
4
5
6
7
8
9
10
| void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
|
扩容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
boolean oldAltHashing = useAltHashing;
useAltHashing |= sun.misc.VM.isBooted() &&
(newCapacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
boolean rehash = oldAltHashing ^ useAltHashing;
transfer(newTable, rehash);
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
|
复制数据到新数组
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
|
循环链表触发的场景网上很多博文,我就不再重复了,找了一篇写的非常好的博客提供参考。
循环链表形成请移步:https://zhuanlan.zhihu.com/p/81587796
循环链表比较难理解,但是多线程环境下还有另外两个更加易发的问题:
如果多个线程同时使用 put 方法添加元素,而且假设正好存在两个 put 的 key 发生了碰撞(根据 hash 值计算的 bucket 一样),那么根据 HashMap 的实现,这两个 key 会添加到数组的同一个位置,这样会导致后面执行的线程把前面线程的数据覆盖了。
如果多个线程同时检测到需要扩容,多个线程在同时进行扩容,都在重新计算元素位置以及复制数据,每个线程都会把新数组重新赋值 给table,同样的后面执行的线程把前面线程的数据覆盖,如果前面执行的线程往数组增加了新元素,那就直接被覆盖导致数据丢失。相比第一点来说第二点是直接整个数组覆盖。数据丢失风险更高。