虚拟机-系统与进程的通用平台
/ / 阅读耗时预计 1 分钟2.4.1 IA-32的解释
下图显示的是IA-32指令的一般格式。
| 前缀 | 操作码 | 操作码 | ModR/M | SIB | 偏移量 | 立即数 |
|---|---|---|---|---|---|---|
| 0到4 | 可选的 | 可选的 | 可选的 | 0,1,2,4字节 | 0,1,2,4字节 |
它以0~4个前缀字节开头,指明是否有字符串指令的重复和/或者是否有对寻址段、地址大小和操作数大小的改写。
在前缀字节(如果有)之后就是操作码字节,它的户名还可能有第二个操作码字节,这取决于第一个的值。
接下来的是可选的寻址方式标识符ModR/M,该表示服是可选的,意味着它只针对某些操作而存在,通常指示一种寻址方式和寄存器。
SIB字节只针对某种ModR/M编码而存在,它指示一个基址寄存器、一个索引寄存器和一个用于索引的比例因子。
可选的、偏移量是针对某些内存寻址方式而存在的。
如果操作码需要,最后一个域是一个边长的立即数。
第二章小节
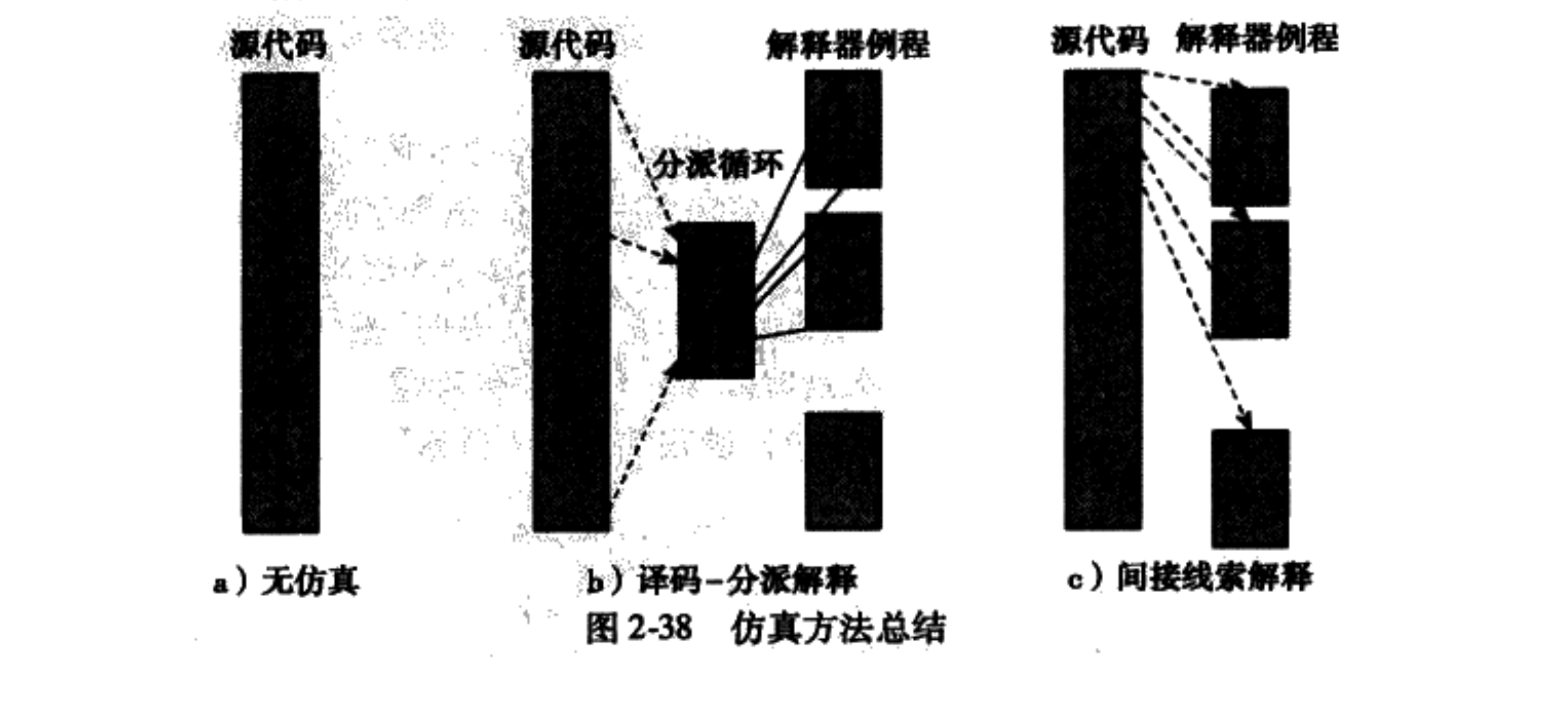
译码-分派解释
内存需求:低——在目标ISA中对每条执行类型有一个解释过程。
启动性能:块——实质上有零启动时间,因为没有对源二进制代码预处理或者翻译的需要。
稳态性能:慢——一条源指令在被仿真时都必须被解析。此外,源代码必须通过数据cache被取得,这给cache带来了很多压力(并且导致了潜在的性能损失)。最好,这种方法会引起大量的控制转移(分支)。
代码可移植性:好——如果解释器用高级语言编写,那么它非常易于移植。
间接索引解释
内存需求:低——比译码-分派解释需要更多内存,因为在每个解释器例程中必须包含分派代码序列。额外内存数量依赖于译码的复杂性;对于RISC ISA它会相对低,而对于CISC它则要高得多。通过混合实现可以减轻内存代价。
启动性能:块——和译码-分派解释一样,实质上有零启动时间;没有预处理的需求。
稳态性能:慢——这会比译码-分派稍微好一些,因为消除了一些分支指令;和译码-分派解释器一样,有高数据cache利用率。
代码可移植性:好——解释器代码和译码-分派解释器一样易于移植。
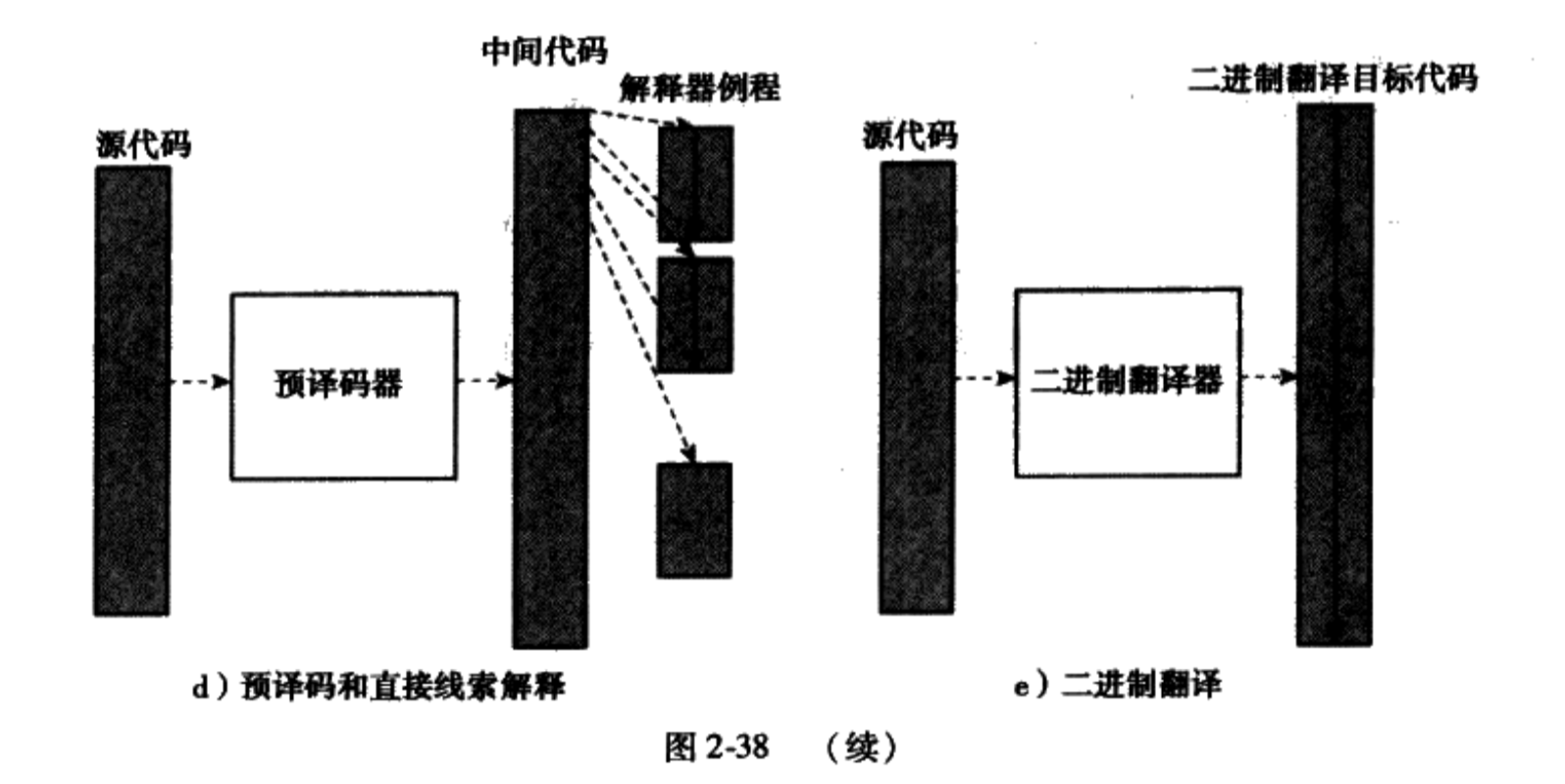
带有预译码和直接线索解释
内存需求:高——预译码内存映像的大小与初始源代码映射是成比例的(并且可能大一些)。如果中间形式被缓存,从cache中删除很少使用的预译码指令块,那么内存需求可以稍微降低。
启动性能:慢——源内存映像必须首先被解释,以便发现控制流。同样,产生被译码的中间形式也要消耗时间。
稳态性能:中等——这要比间接线索好,因为每次执行各个指令时不必对它们解析(和译码)。如果预译码形式包含解释程序的目标地址,那么分派表查找就被消除。因为预译码指令仍然被解释器代码当作数据来处理,所以数据cache利用率高。
代码可移植性:中等——如果预译码版本包含解释器例程的具体位置,那么解释器就变得依赖于实现了。支持发现标号地址的编译器可以减少这个缺点。
二进制解释
内存需求:高——预译码内存映像的大小与初始源内存映像是成正比的。如果翻译代码块被缓存,可以降低预译码的内存需求。
启动性能:非常慢——源内存映像必须首先被解释,以便发现控制流。然后必须产生翻译二进制代码。
稳态性能:快——翻译二进制代码直接在硬件上执行。如果翻译块直接链接起来,性能会提高甚至更多。此外,由于翻译代码被渠道指令cache中,这减轻了对出具cache的压力。
代码可移植性:差——代码被翻译成特性的目标ISA,对于每个目标ISA必须写一个新的翻译器(或者至少是代码生成部分)。